Google Cloud Vision API with Java
以下說明如何在 Java 中使用 Google Cloud Vision API。
- 前往 Google Cloud Console https://console.cloud.google.com/
- 建立一個專案。
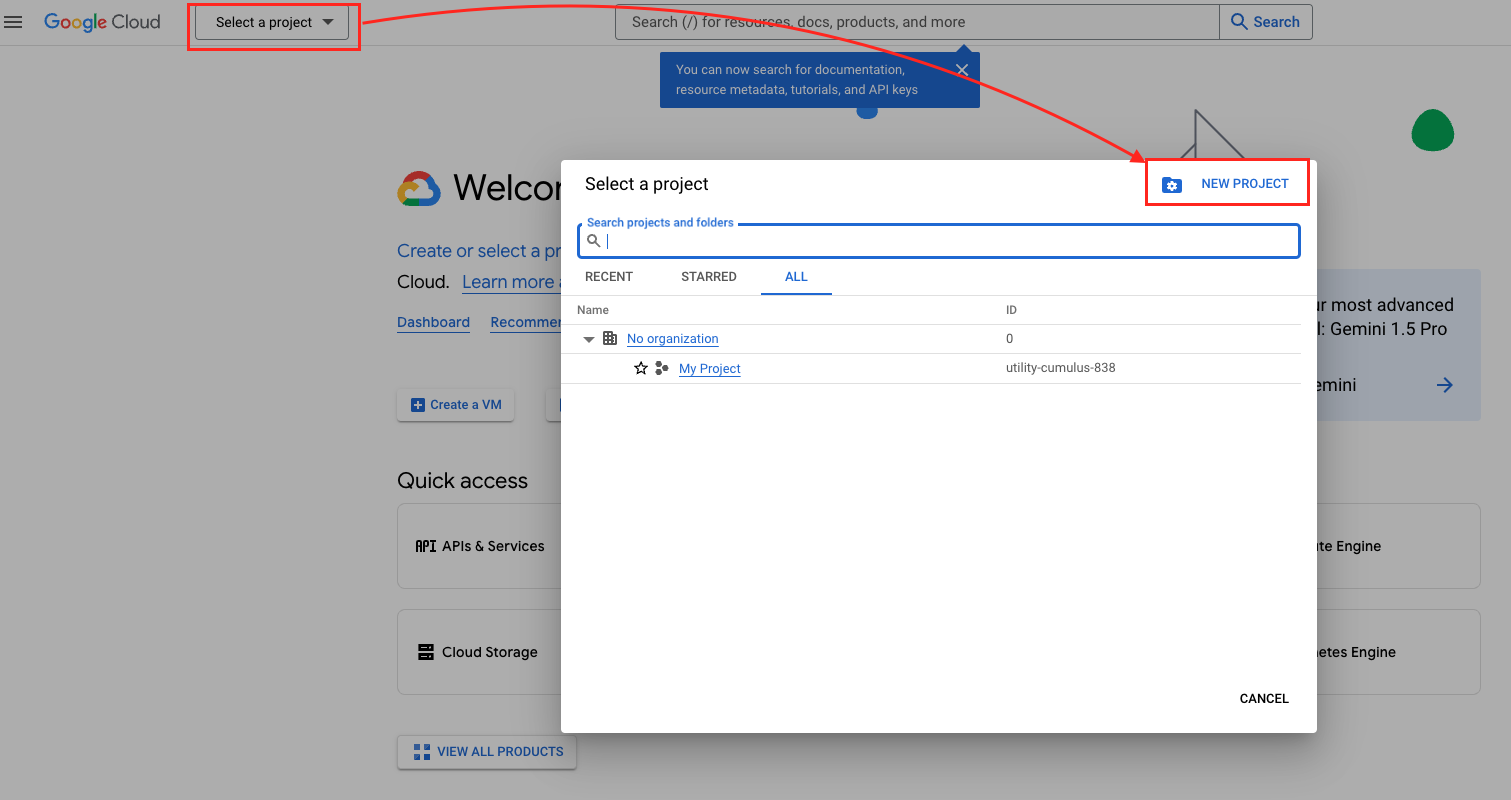
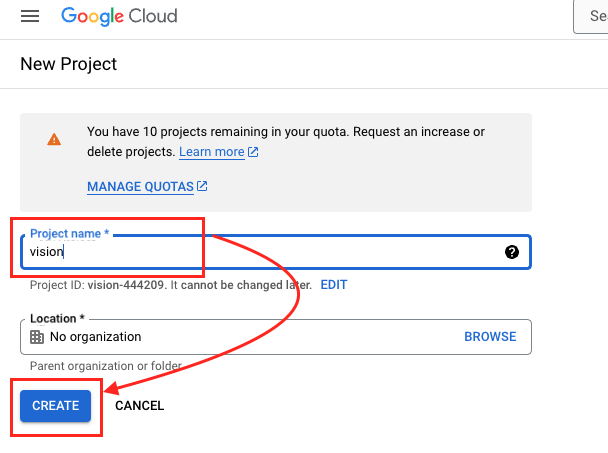
- 輸入專案名稱。
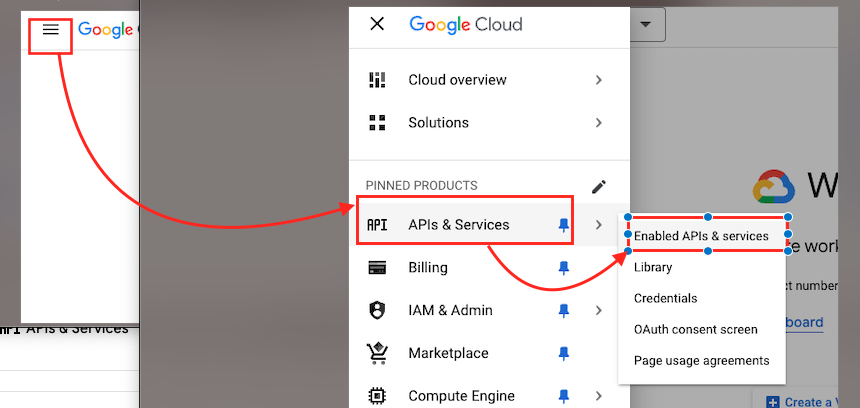
- 選擇 APIs Services -> Enabled APIs & services。
- 選擇 ENABLED APIs AND SERVICES。
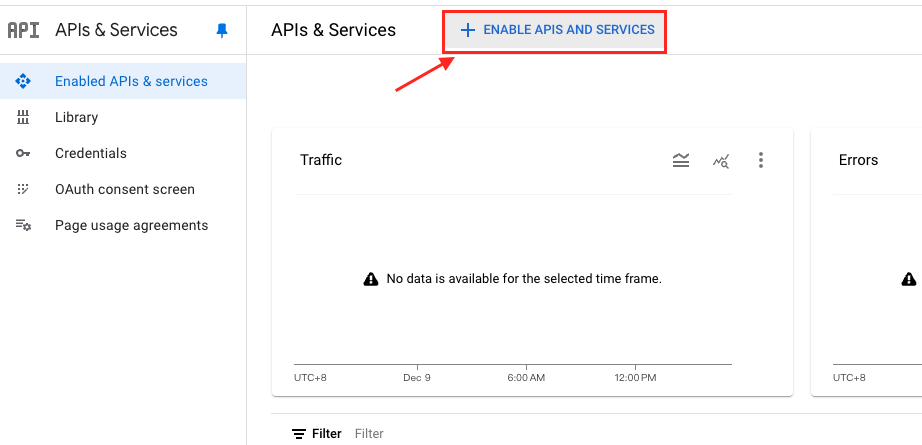
- 在搜尋框中輸入
vision。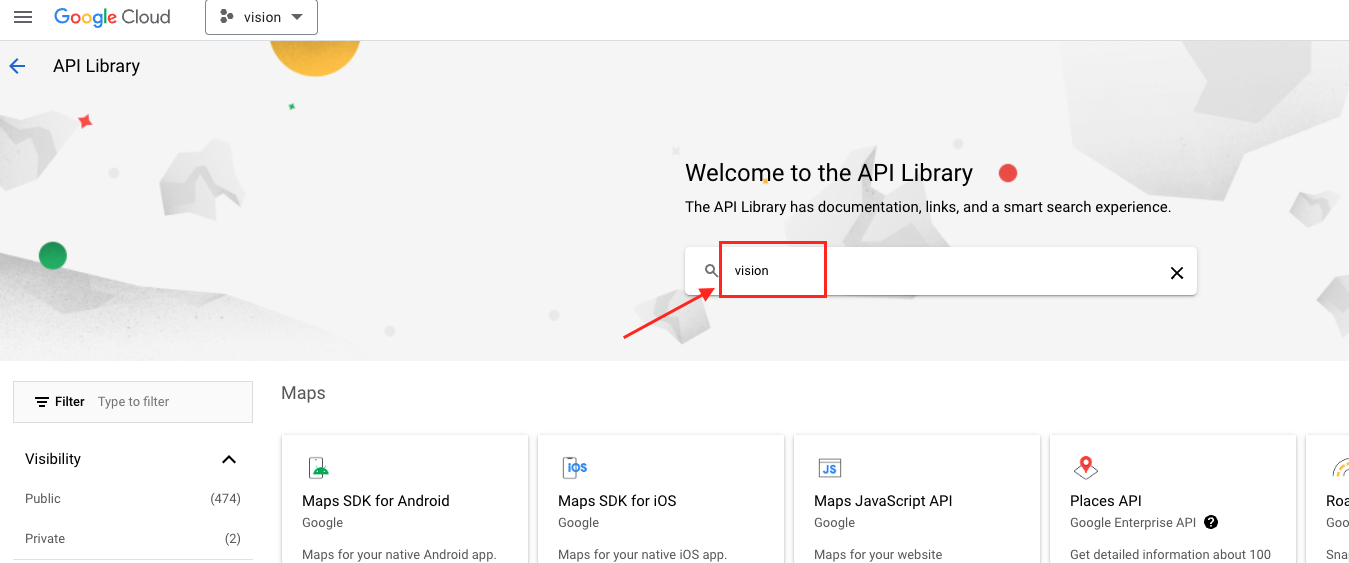
- 找到
Cloud Vision API點擊進入。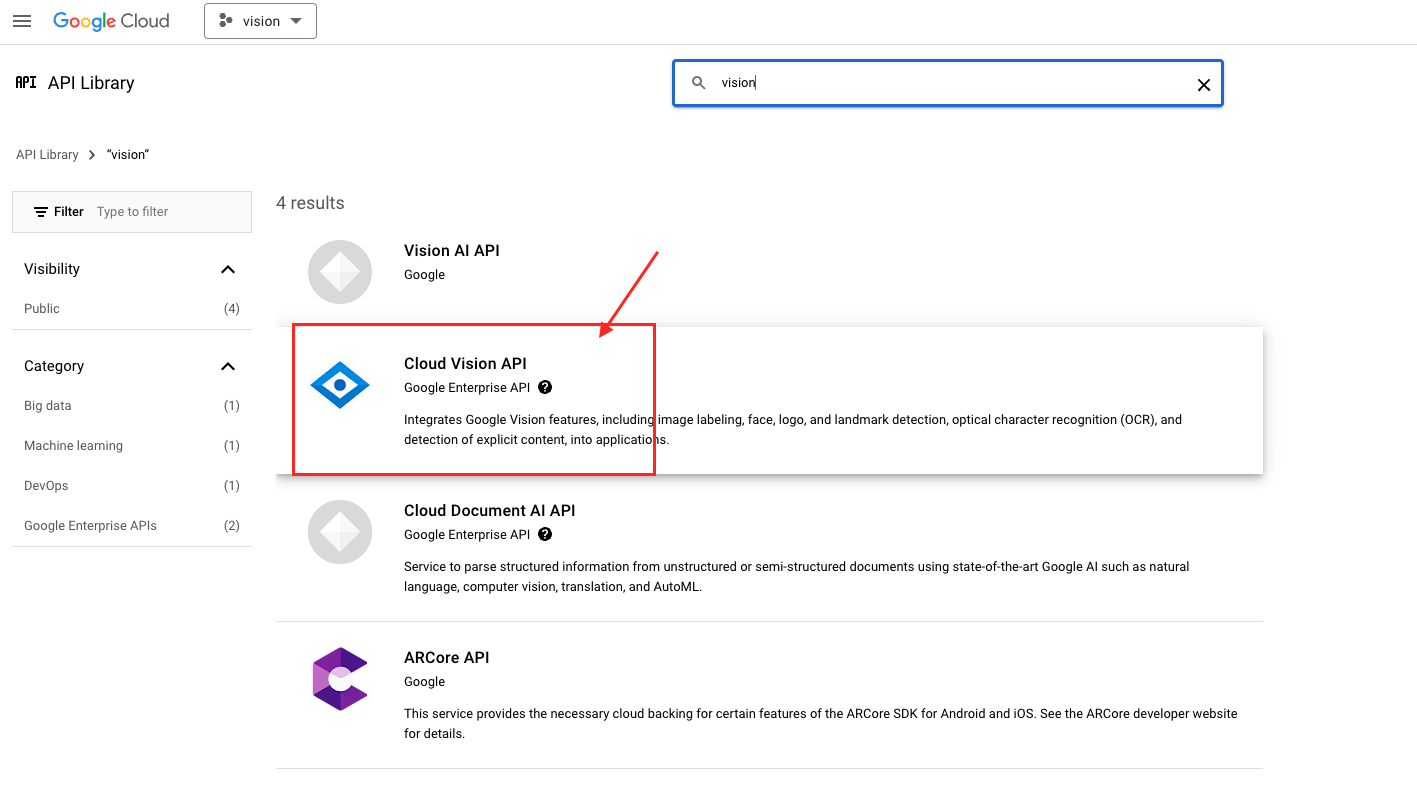
- 啟用這個
Cloud Vision APIAPI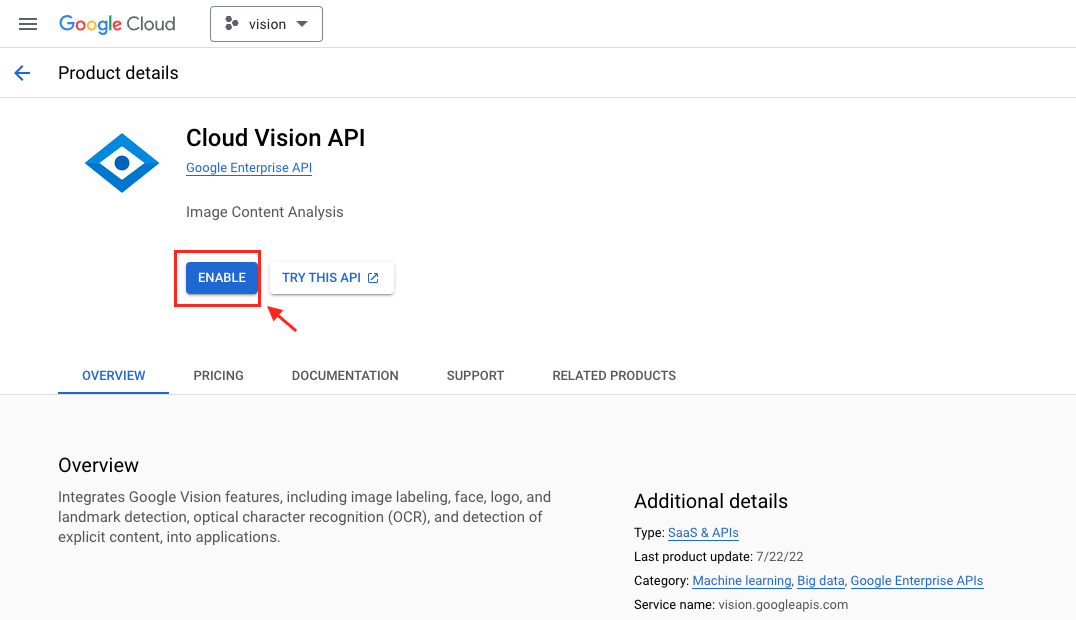
- 建立一個 Service account 。選擇
Credentials->+ CREATE CREDENTIALS->Service account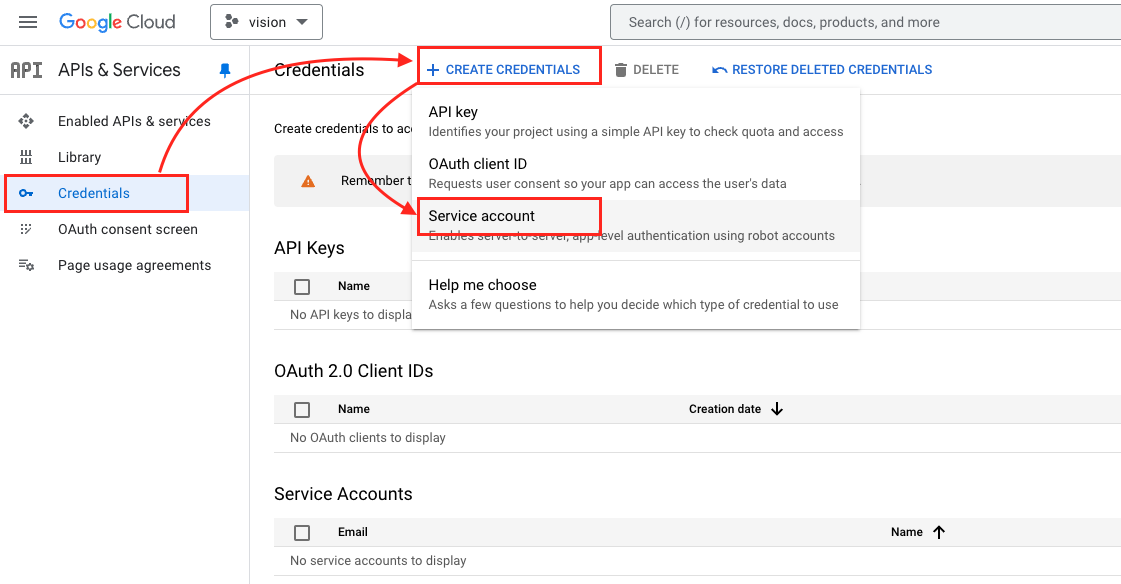
- 輸入 Service account 的 name 與 ID 並選擇
CREATE AND CONTINUE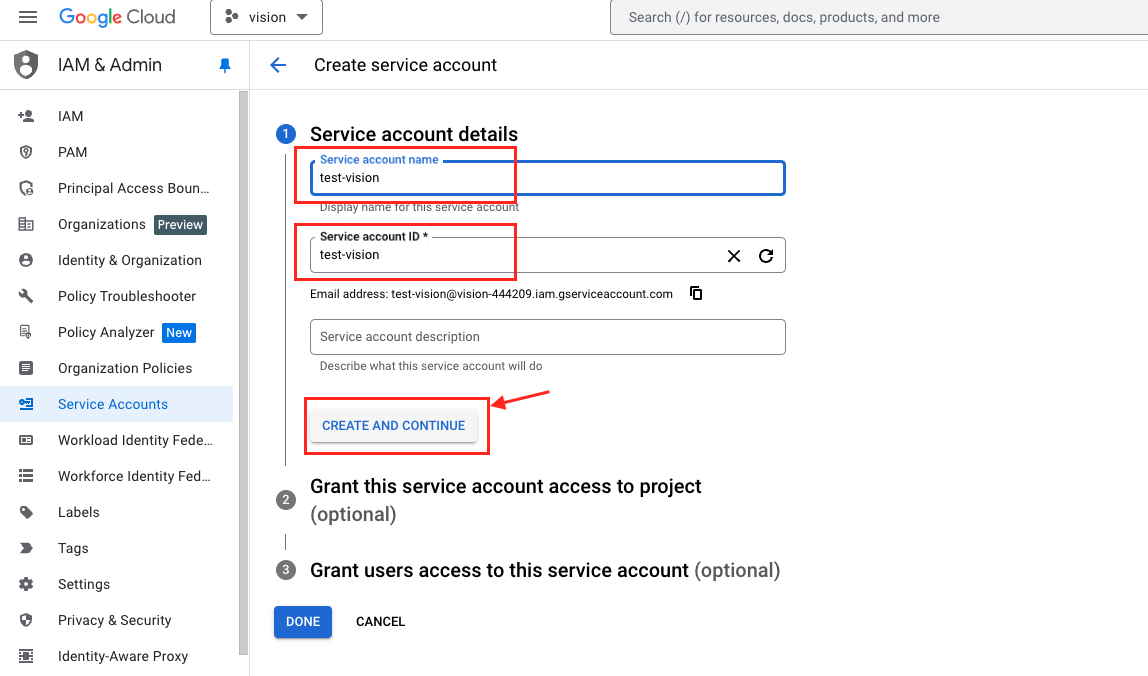
- 第二步,可以跳過,選擇
CONTINUE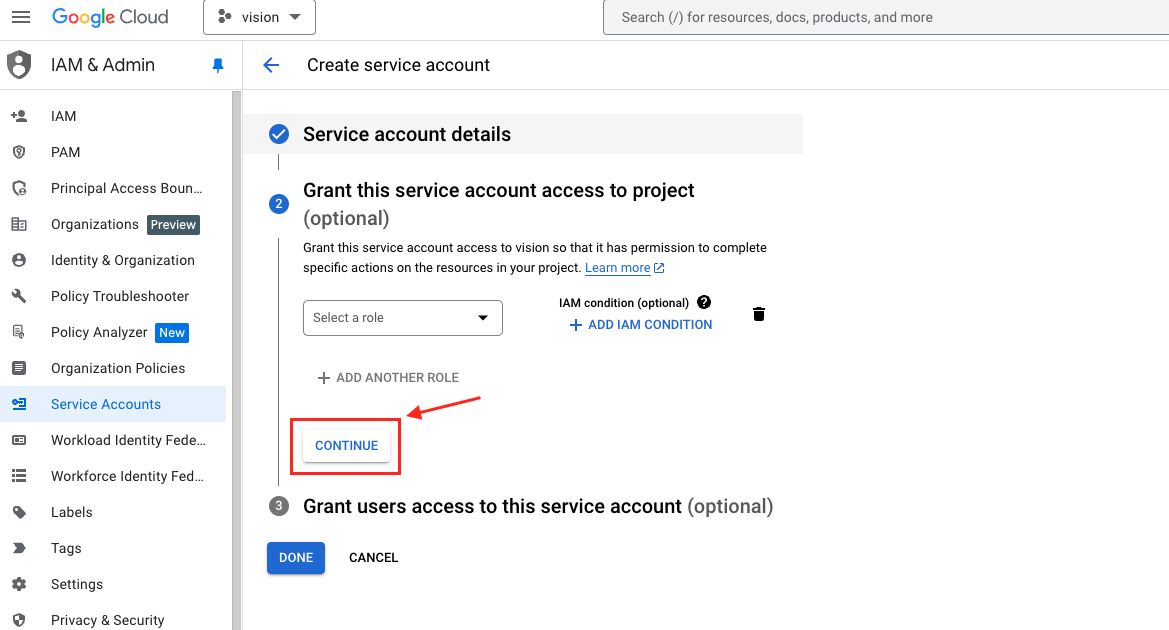
- 第三步,可以跳過,選擇
DONE,建立 Service Account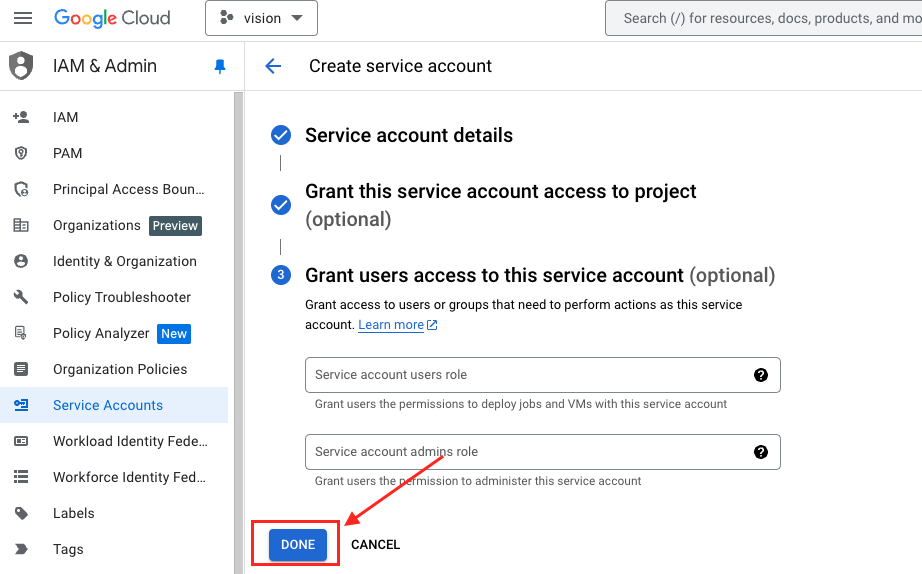
- 點擊剛剛建立的 Service Account
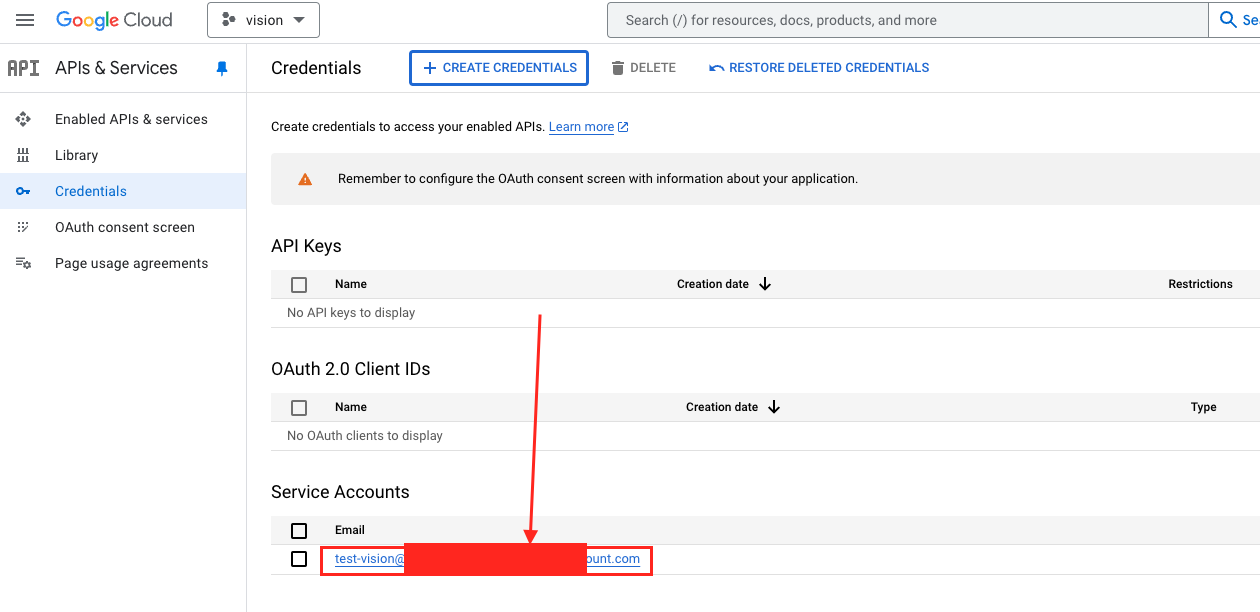
- 選擇
KEYS->ADD KEY->Create new key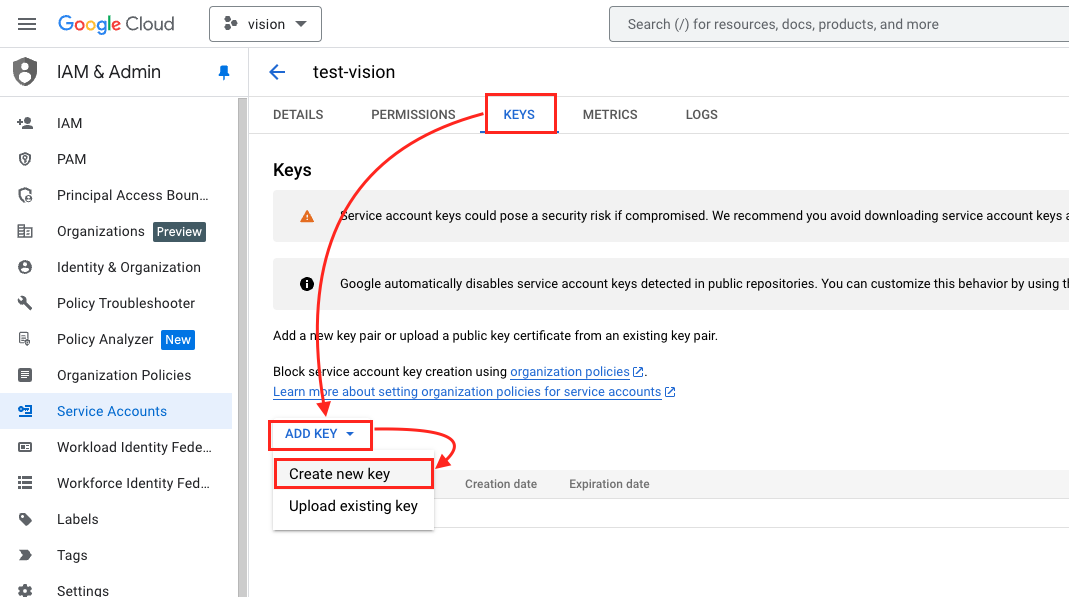
- 選擇
JSON,就會產生一個 JSON 檔案,供之後 Java 程式使用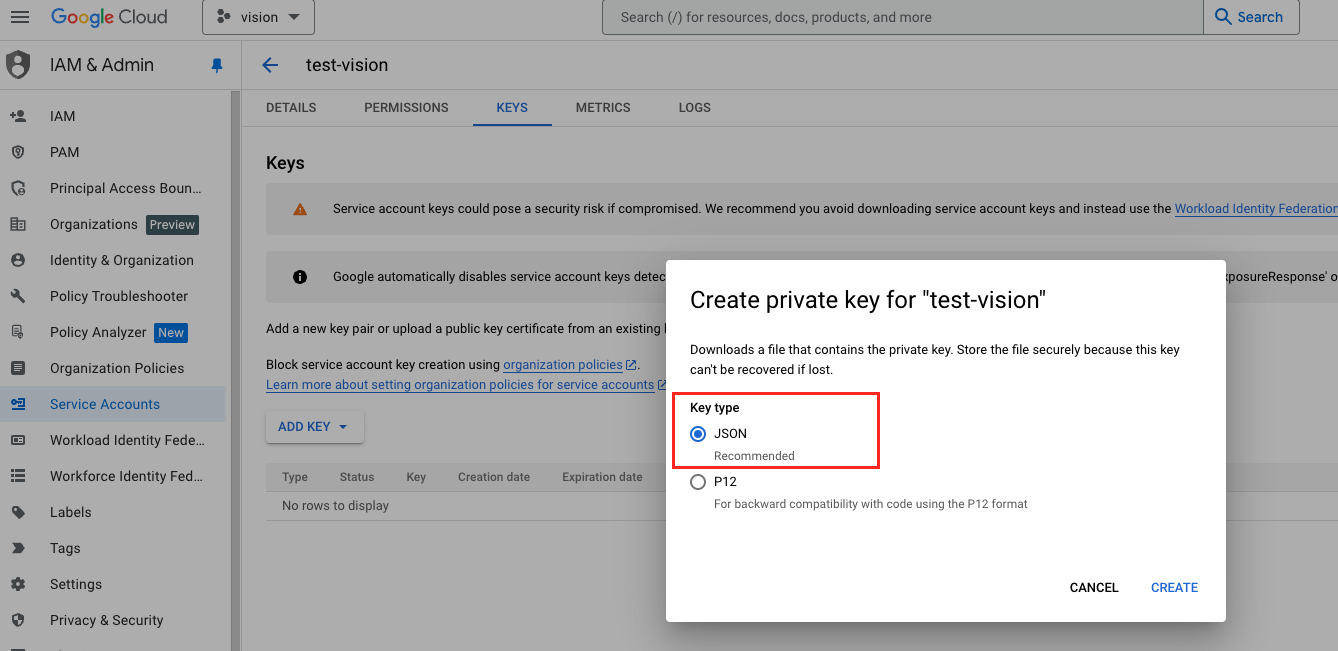
- 建立一個 Java 專案,並引用 google-cloud-vision 依賴,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.50.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-vision</artifactId>
</dependency>
</dependencies> - 在程式碼中使用以下程式碼引入上面建立的 GoogleCredentials
1
2GoogleCredentials credentials = GoogleCredentials
.fromStream(new FileInputStream("<在步驟15產生的json檔案>")); - 使用以下程式碼將 圖片文字的 Pdf 轉為 文字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49public static void processPdf() throws IOException {
GoogleCredentials credentials = GoogleCredentials
.fromStream(new FileInputStream("<在步驟15產生的json檔案>"));
ImageAnnotatorSettings imageAnnotatorSettings = ImageAnnotatorSettings.newBuilder()
.setCredentialsProvider(FixedCredentialsProvider.create(credentials)).build();
try (ImageAnnotatorClient vision = ImageAnnotatorClient.create(imageAnnotatorSettings)) {
String fileName = "./image-based-pdf-sample.pdf";
Path path = Paths.get(fileName);
byte[] data = Files.readAllBytes(path);
ByteString pdfBytes = ByteString.copyFrom(data);
InputConfig inputConfig = InputConfig.newBuilder().setMimeType("application/pdf") // Supported MimeTypes:
// "application/pdf",
// "image/tiff"
.setContent(pdfBytes).build();
Feature feature = Feature.newBuilder().setType(Feature.Type.DOCUMENT_TEXT_DETECTION).build();
AnnotateFileRequest request = AnnotateFileRequest.newBuilder().setInputConfig(inputConfig)
.addFeatures(feature).build();
List<AnnotateFileRequest> requests = new ArrayList<>();
requests.add(request);
BatchAnnotateFilesResponse response = vision.batchAnnotateFiles(requests);
List<AnnotateFileResponse> responses = response.getResponsesList();
for (AnnotateFileResponse res : responses) {
if (res.hasError()) {
System.out.format("Error: %s%n", res.getError().getMessage());
return;
}
int pageSize = res.getTotalPages();
System.out.println("pageSize = " + pageSize);
for (int i = 0; i < pageSize; i++) {
AnnotateImageResponse annotateImageResponse = res.getResponses(i);
System.out.format("%nText: %s%n", annotateImageResponse.getFullTextAnnotation().getText());
}
}
}
} - 使用以下程式碼,可以辨認圖片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public static void image() throws IOException {
GoogleCredentials credentials = GoogleCredentials
.fromStream(new FileInputStream("<在步驟15產生的json檔案>"));
ImageAnnotatorSettings imageAnnotatorSettings = ImageAnnotatorSettings.newBuilder()
.setCredentialsProvider(FixedCredentialsProvider.create(credentials)).build();
try (ImageAnnotatorClient vision = ImageAnnotatorClient.create(imageAnnotatorSettings)) {
String fileName = "./test.jpg";
Path path = Paths.get(fileName);
byte[] data = Files.readAllBytes(path);
ByteString imgBytes = ByteString.copyFrom(data);
List<AnnotateImageRequest> requests = new ArrayList<>();
Image img = Image.newBuilder().setContent(imgBytes).build();
Feature feat = Feature.newBuilder().setType(Type.LABEL_DETECTION).build();
AnnotateImageRequest request = AnnotateImageRequest.newBuilder().addFeatures(feat).setImage(img).build();
requests.add(request);
BatchAnnotateImagesResponse response = vision.batchAnnotateImages(requests);
List<AnnotateImageResponse> responses = response.getResponsesList();
for (AnnotateImageResponse res : responses) {
if (res.hasError()) {
System.out.format("Error: %s%n", res.getError().getMessage());
return;
}
for (EntityAnnotation annotation : res.getLabelAnnotationsList()) {
annotation.getAllFields().forEach((k, v) -> System.out.format("%s : %s%n", k, v.toString()));
}
}
}
}
整個 Java 程式碼
1 | package ultrasigncorp.vision; |
Reference: